2025-01-17 如何构建一个稳健可靠的系统
问题描述
服务在高峰期被流量打挂,看表象很容易以为是预估不到位,机器资源不够,但其背后深层次的原因是服务本身不够健壮,服务在短暂的过载之后发生雪崩,进而引发重试风暴,如果这些服务是主流程、核心链路上的服务,那么就有可能导致整个系统的雪崩。一个稳健的系统,在负载压力增大,甚至超出理论最大负载时依然能够稳定的保持线性输出。那么如何构建一个稳健可靠的系统? 首先了解如下系统性能指标概念:
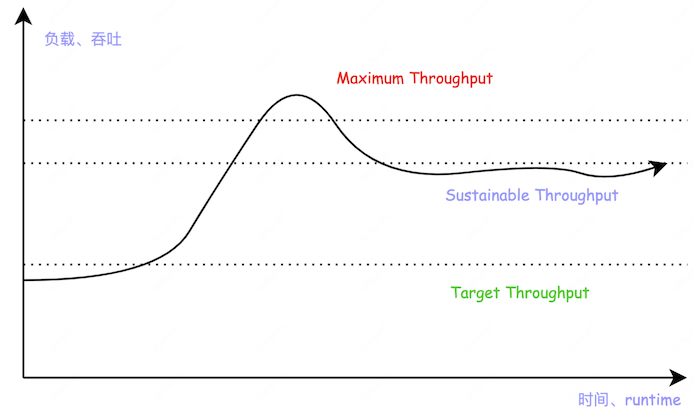
- 最大吞吐:绝大数情况下,我们的服务不会处于最大吞吐状态,它只是昙花一现。高负载状态下随着时间的推移,服务的队列和延迟会无限增加。
- 持续吞吐:服务延迟可控状态的下的可持续的性能吞吐。
- 目标吞吐:根据真实服务负载评估出的用于扩容的吞吐量。
Maximum Throughput:
a situation that happens as a flash in the pan moment where the state of the system aligns perfectly for unusually high throughput. Most of the time our system is not capable of maximum throughput. If we drive the system at this level then over time our latency will be unbounded because of queue growth. This is useless information for our purposes.
Sustainable Throughput:
the throughput that our system can sustain indefinitely without latency becoming unbounded. This number is always less than the maximum throughput. If a system is driven above its sustainable throughput, it will either fail requests or see its latency grow without bound.
Target Throughput:
the real world throughput we use for scaling decisions. We will plan to divide the externally provided load among enough instances of our service so that each instance, on average, remains below its target throughput. We choose this value conservatively such that brief spikes in load or reductions in capacity do not cause us to violate our latency requirements. This value must be less than the sustainable throughput.
构建方法
- 负载指标:健壮的服务应该具备完善的表征系统负载的指标,如资源利用率,计数器,队列状态,请求延迟等
- 拒绝服务:一个服务除了能够实时表征自己服务负载的指标之外,应该感知这些指标并且当超出服务能力上限时,拒绝超出服务能力的请求。
- 反馈机制:服务端和客户端之间要有反馈机制,客户端能够知晓后端的负载情况,调整自己的策略。
问题解答
-
我的服务对延迟和队列没有要求
- 任何服务处理请求都有延迟。如果不要求延迟指标,只代表"max latency < infinity",理论上依然存在一个界定点来区分服务的最大吞吐量和持续吞吐量。
- 任何服务都有请求队列,有时功能可能迁移到了用户端。
-
队列是错误的存在吗?
- 本质上非阻塞队列以增加的延迟换取更高的可用性。当上游需求出现峰值时,队列让系统通过增加处理延迟来吸收峰值,而不是让请求失败。
- Throughput dependent latency is always caused by queue growth
- Queues should not be growing if the system is running within its capacity.
-
反馈机制是否可以通过外部监控+流量降级方案替代?
- 监控是有滞后的,流量降级是有损的,这导致降级需要谨慎。这些因素都决定了,外部监控+流量降级这套机制,是用来解决故障,而非让服务更加健壮的。服务的健壮性本身,要依赖服务自身来解决。
-
如何统一所有客户端服务端反馈机制?
- RPC 框架
参考
最后更新于: 2025 年 03 月 27 日。 阅读量: 9。 链接地址: https://blog.bamaicloud.com/posts/2025-01-17-how-to-build-stable-systems/